Practical setup for Data Mesh approach


Share

Working with data in a big company can be very tiresome, and that is to put it lightly. Ever-growing volumes of data, flowing in from frequently added streams, with even more logic to transform, shape, and load all of that “fluid” into some required form for later use, are becoming more and more challenging tasks with each passing day.
What is Data Mesh?
Data Mesh is in pure basics based on an age-old divide and conquer strategy. Instead of building a monolith and desperately throwing more bodies in an attempt to keep it afloat, this strategy instead opts for a path of creating and dividing the giant monolith into a set of smaller, much more robust systems that are simpler and easier to use. And hence require considerably less human resources to maintain.
Data Mesh is a relatively new-and-hot paradigm discussed in various data-related events, forums, and data-oriented communities. One of the first popular mentions of Data Mesh was by Zhamak Dehghani in the original post “How to Move Beyond a Monolithic Data Lake to a Distributed Data Mesh” on the Martin Fowler website.

The overall concept of it is fascinating. Instead of combining all your data streams and inputs under a single roof of a Data Lake, it rather suggests a bit different approach for distributing various data streams and their respective data processing capabilities onto smaller separate pieces called domains. The idea of domains is thrilling in and of itself. A domain would describe a collection of knowledge of a specific part of the data stream, combined with all the technologies required to Extract, Load, Transform and Store that stream of data and possibly even part of the technology set used to analyze and present said data.
Why it can be useful
Working with data in a big company can be very tiresome, and that is to put it lightly. Ever-growing volumes of data, flowing in from frequently added streams, with even more logic to transform, shape, and load all of that “fluid” into some required form for later use, are becoming more and more challenging tasks with each passing day. It seems like after some point in time, adding more members to a data-engineering team gives less and less positive feedback, which probably means that the problem can be somewhere else.

My interpretation of this would be to call the Data Mesh strategy a collection of tiny data warehouses interconnected in a web where each one is built following one of UNIX philosophical principles: to do one thing and do it well. Additionally, the knowledge that responsible people have about their specific area becomes an asset in and of itself. I believe it serves much better in the long run, cutting the future time that one would spend digging through the data pools trying to connect the dots while attempting to build something from that data.
What could be a technology set
In the article and the talks, the author suggests that we are not yet at the stage where technology is ready for this approach directly. However, some existing solutions could be combined to achieve something similar to the original vision, and I will try to describe each and every one of those.
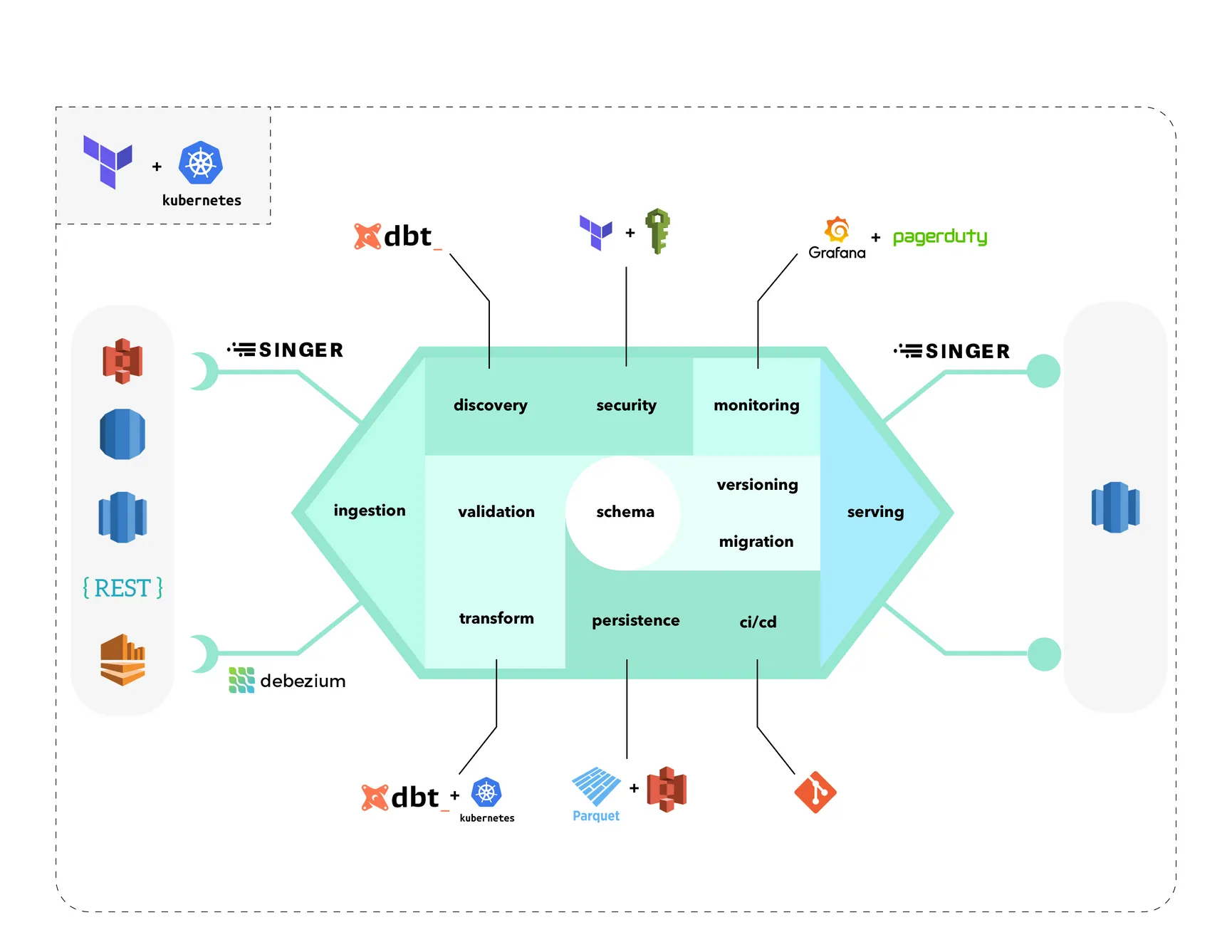
Data ingestion
Both https://singer.io and https://debezium.io/ look like great products that can be leveraged to ingest the data into the nano warehouse.
Debezium is a tool that focuses on fetching the changes from operational databases by applying a “diff” strategy of sorts, only virtually. It could be instrumental to continuously import more minor changes rather than duplicate tera- and petabytes of data each time you plan to do the scheduled import.
Singer, however, is a beast of its kind. It’s not necessarily a tool but rather a collection of tiny, standardized, open-source modules that can be used to fetch and push data from and to an ever-growing list of integrations. You can find almost any popular and not-so-popular tool you ever used and some implementation for data ingestion or data retrieval for it on someone’s GitHub account.
Data schema and persistence
In the center of everything, there is a data schema. It does not have a distinct technology yet, but something like DBT, I think, came very close. A language or a specification that would allow you to describe the data you are importing, how it should be stored and monitored, the policies that should be applied to specific fields and tables, and possibly even the way it should be served.
The ingested would then be transformed on-the-fly to a format specified by the schema and stored not in a data warehouse database but rather on a distributed file system with a highly-efficient parquet file format. This allows for storing much more data (like full everyday snapshots of the target databases) while keeping the costs relatively low. And to leverage DBT and other tools, some file-based database integration for querying tools can be used, like Redshift Spectrum for Redshift and similar instruments.
Discovery, transformation, and validation
I would consider a DBT-powered setup to be my favorite in this “race”. The ability to define transformations and relations between lower and higher dimension models while in the background also using git and wiring everything in plain SQL is like a revelation! DBT could be used to document the fields, create SQL-only transformations, and do test-based data validations. And something like Kubernetes could be used on the backend to keep things running while we work our magic here.
Security and monitoring
A combination of cloud-service provider identity management platforms and built-in database user management systems could be put in place to control which tables, fields, file-based parquet sets, singer pipelines, and event logs are accessible by which parts of the team. Additional privacy policies attached to specific columns described by the schema could regulate which portions of the data would be accessible by your organization members.
Monitoring would play a big part in understanding what is happening with such a nano warehouse. Tools like Grafana could help to see an accurate real-time picture of what is going on, how it is going, and if there is anything wrong.
Migration, versioning, and CI/CD
One of the essential functions of a system backed by the schema is to define what should happen with such a system in case schema changes. An excellent solution for this, I think, would be adding a flow that would allow a zero-downtime migration to be applied, that would transfer and modify/migrate all the data gathered by the previous instance of this nano warehouse to a new schema/format.
After the migration is complete, both instances (old and new) should be kept in a working state, and both should be connected to the same inputs. This would allow for all dependent users of those nano warehouses, whether that would be analysts, dashboards, or other nano warehouses, to slowly and carefully migrate to the new data schema without triggering any significant outages in the data pipelines and reporting/business processing layers.
And CI/CD would be the layer that would initiate all the required steps, including migrations, validations, schema tests, and other related activities.
Conclusion
Data Mesh is indeed a very intriguing concept and something that could potentially make all our lives a bit simpler and happier :)
The technology set provided in the article can be different for different use-cases. But overall, I think this should at least give a general idea of how the Data Mesh approach can be leveraged today and what current tools could be used to build something like this for your organization.