Using Fivetran and dbt to Extract and Transform Data

Share

Data pipelines and the tools used to build and maintain them are becoming increasingly complex and difficult to manage. These pipelines are the vital organs of your data-driven business, taking data from its source, storing it, and transforming it for analysis. Without accurate, on-time data, important decisions may be delayed and mistakes may be made, hindering your company’s growth.
Data is constantly being made available in greater quantities and from more sources. Web and user analytics, e-commerce, advertising, and direct feedback are among the many potential sources of data — each with its own differing formats and standards.

As businesses scale up, it becomes increasingly difficult to consume and transform this data. Put simply, more sources + more users = exponentially more data. Data quality and delivery time suffer as engineers spend more time maintaining the infrastructure required for the increasing flow of data.
Data experts who work day to day with large volumes of data are now favoring simplified toolchains that allow them to focus on the data itself rather than the infrastructure carrying and transforming it.
Fivetran and dbt are two tools that can be used together to form a remarkably simple — but incredibly powerful — ELT data pipeline. This article will explain how and why we are using these two solutions together to create automatic data pipelines, which benefit from the time savings of data consumption as a service and the versatility and safety of in-house warehousing and processing.
ELT pipelines — a refresher
ELT (extract, load, transform) data pipelines work on data in three steps that bring it from its source to a format that is ready for interpretation and analysis:
- Extract: Consume the data from the source.
- This stage involves reading the data from an external service, like Google Analytics, Shopify, social media, etc.
- Load: Save the data from the source to your own storage — usually a database or
data warehouse.
- The data is saved in the format it is provided in, with no additional transformation taking place at this stage, reducing the processing resources required.
- Transform: Manipulate the data into the final format in which you wish to view or
operate on it.
- The data is transformed as required. As only the relevant data for the current task is transformed, processing time and requirements are decreased.

ELT is an improvement on the ETL (extract, transform, load) pipeline, which is more complex. ETL requires more processing overheads, as all of the incoming data must often be transformed to meet quality standards or standardized formats before it is loaded.
What are Fivetran and dbt?
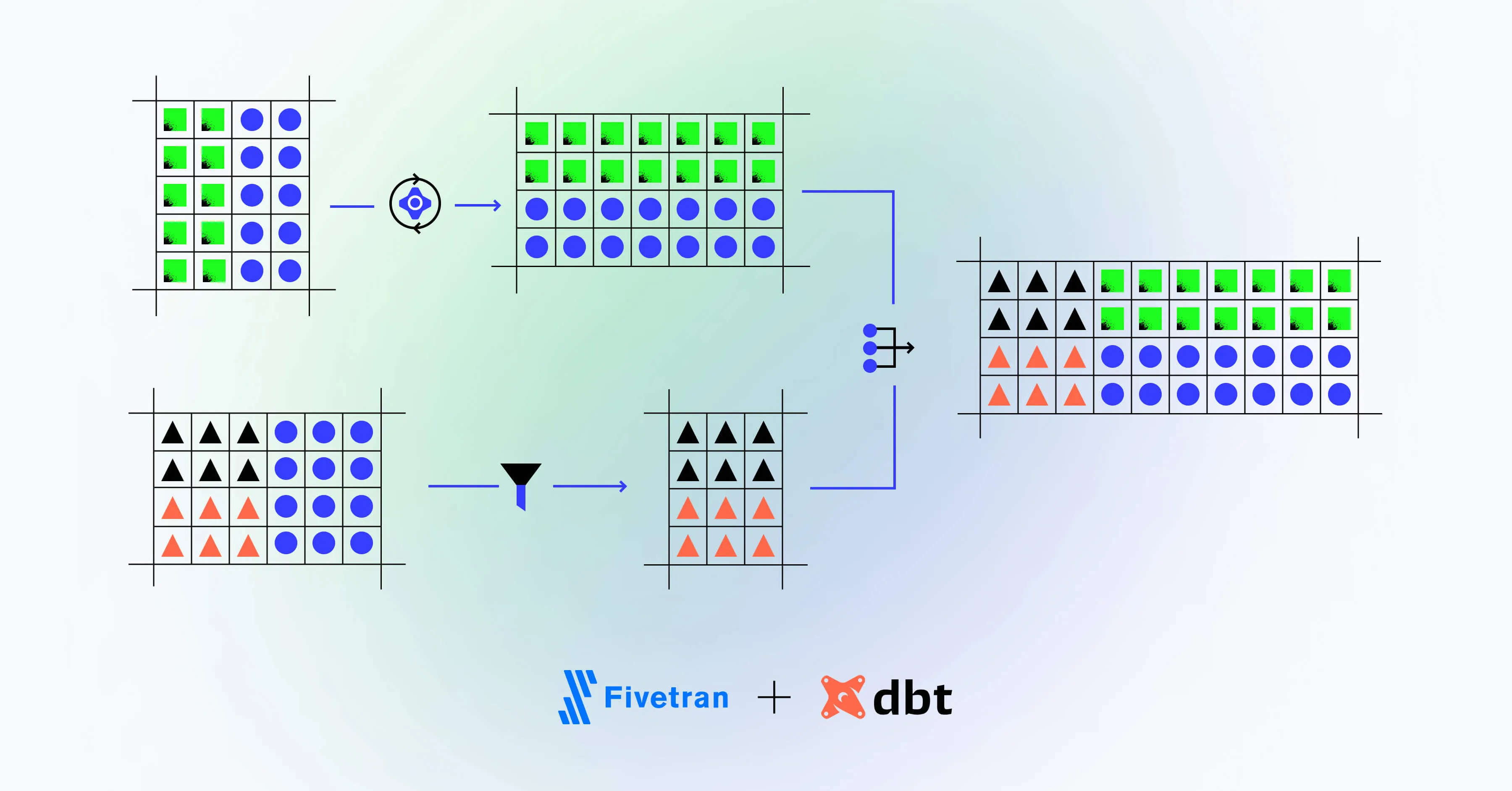
Fivetran is an online platform for building ELT data pipelines. It allows you to consume data from any number of sources — in different structures and formats — and host it in centralized data warehouses on Amazon Web Services (AWS), Google Cloud Platform (GCP), or Microsoft Azure public cloud environments.
Fivetran takes the hassle out of building ELT pipelines, simplifying the process with a platform as a service that doesn’t require any additional infrastructure management or maintenance. It lets you focus on your models and provides a “clean” feed from your data source to the warehouse.
dbt (data build tool) is a data transformation tool. It does all of its work within the data warehouse — there are no external tools that require infrastructure or additional orchestration. Everything in dbt is effectively a SQL SELECT statement, so the syntax is easy to pick up for those already working with databases.
dbt focuses on doing one thing and doing it incredibly well — handling the transform step in an ELT pipeline. Fivetran can efficiently handle the extract and load stages, and as neither tool requires additional infrastructure, they can be combined to create a streamlined but flexible pipeline.
Our recommended approach to ELT with Fivetran and dbt

At Mighty Digital, we are smitten with the combination of Fivetran and dbt. Since adopting it for our ELT workflows, we have spent significantly less time implementing and debugging infrastructure, while a DevOps approach to dbt leaves us more time to ensure that the data we are collecting undergoes the best possible processing and analysis. Our clients receive high-quality information and insights faster, allowing for more accurate and informed decision-making.
How we’re using Fivetran
Fivetran is capable of pulling data from almost any source using its connectors functionality. A huge array of popular data sources are supported out of the box, including services such as Google Analytics, Shopify, Apple and Google’s app stores, social media, and pretty much every major online service that allows you to pull data. If you are working with your own data, Fivetran can connect directly to existing databases, or custom connectors can be built.
Fivetran provides us with a pristine data feed from multiple sources, which is then stored in our data warehouse.
Cleaning up with dbt
Once we have our data in the warehouse, we use the dbt packages that Fivetran has generously provided as the basis for our dbt transformations. These packages allow us to use dbt with warehoused data taken directly from Fivetran’s connectors.
We can then further tweak these models or add our own additional modeling on top of this to generate the insights that we require.
Designed to work together
Fivetran has recognized the power of this combination and made dbt a functional part of their platform. The steps to set up Fivetran and dbt are well documented so that you can get up and running with a properly configured ELT pipeline and implement best practices. Fivetran can also be configured to automatically trigger dbt Core transformations as soon as the data has been loaded, through Fivetran’s integrated scheduling feature.
Though Fivetran is a platform as a service, once the data has been extracted and loaded, it is stored in your data warehouse. You retain full control of it and can meet any regulatory or processing requirements or move to a different solution without having to worry about lock-in.

Recommendations for scaling up
As Fivetran is a platform as a service, it handles all of the infrastructure for you. There is no need to plan for additional capacity in the extract stage as the quantity of the data you are collecting increases. Multiple data sources are supported, so as many data providers can be added as needed.
As dbt runs within your data warehouse, it does not have any additional infrastructure that requires scaling.
However, your data warehouse itself will need to be able to grow with your data requirements. The specifics of this will depend on where and how your data is hosted and how long you intend to retain historical data. It may only be a matter of ensuring you are aware of the growing storage requirements and the costs involved and managing or pruning your historical data appropriately.
Organizationally, the combination of Fivetran and dbt allow you to create a centralized “source of truth” — one place where all data is stored and referenced by the departments that require them. You can implement a single, centralized schedule for data transformations to avoid collisions between those accessing the data.
A continuous integration (CI) pipeline can be implemented to store transformations in a repository and rerun the transformations when the repository is updated or at a fixed time when users are unlikely to be impacted. Growing teams can then collaborate on data with the confidence that they aren’t negatively impacting other team members with their ongoing work.
dbt cloud provides a hosted dbt service that includes scheduling and built-in CI functionality, monitoring, alerts, and a web-based interface. Growing organizations with large data requirements may find this further facilitates collaboration and reduces the operational cost of their ETL pipelines as they increase in complexity.
It’s your data — and the future of your business
Here at Mighty Digital, we are always on the lookout for the next big thing in big data — but we are also wary of passing fads and tools with a short lifespan.
When promising tools arrive, we test them thoroughly and work with the data community to make sure that the products we invest in are the best possible tools for the job, with an involved development team, user base, and roadmap to ensure the longevity of any platform we decide to adopt for ourselves and our clients.
We’ve identified Fivetran and dbt as flexible and robust tools in their own right. In combination, they form a powerful toolchain for implementing ELT pipelines that are future-proof and scalable. Configuring Fivetran and dbt is a straightforward process, and the SQL syntax used by dbt enables you to use your existing skills rather than having to learn a new domain-specific query language.
While you can build your ELT pipelines yourself, it pays to have an experienced team build your data solutions to the highest standards and to ensure that you receive high-quality, insightful data when and where you need it. The last thing any data-driven company needs is to reach for important data, only to find it was malformed at some stage of the pipeline, wasting both the data and the resources spent processing and warehousing it.
Get in touch with us today to find out how we can help you get the most out of your data. We are excited about the new solutions we are developing to help you realize the full potential of your data.








