What is a data pipeline?

Share

If your organization has at least some online presence, you might be wondering how to leverage your data. Data points are generated whenever someone signs up for your service, sends you an inquiry, or performs a transaction on your website. While such data is not very informative on its own, it can produce astounding insights when aggregated.
Businesses have understood the power of data and are looking for ways to make it work for them. The first step towards that goal? Building a reliable data pipeline that’s customized to a specific use case.
What Are Data Pipelines?
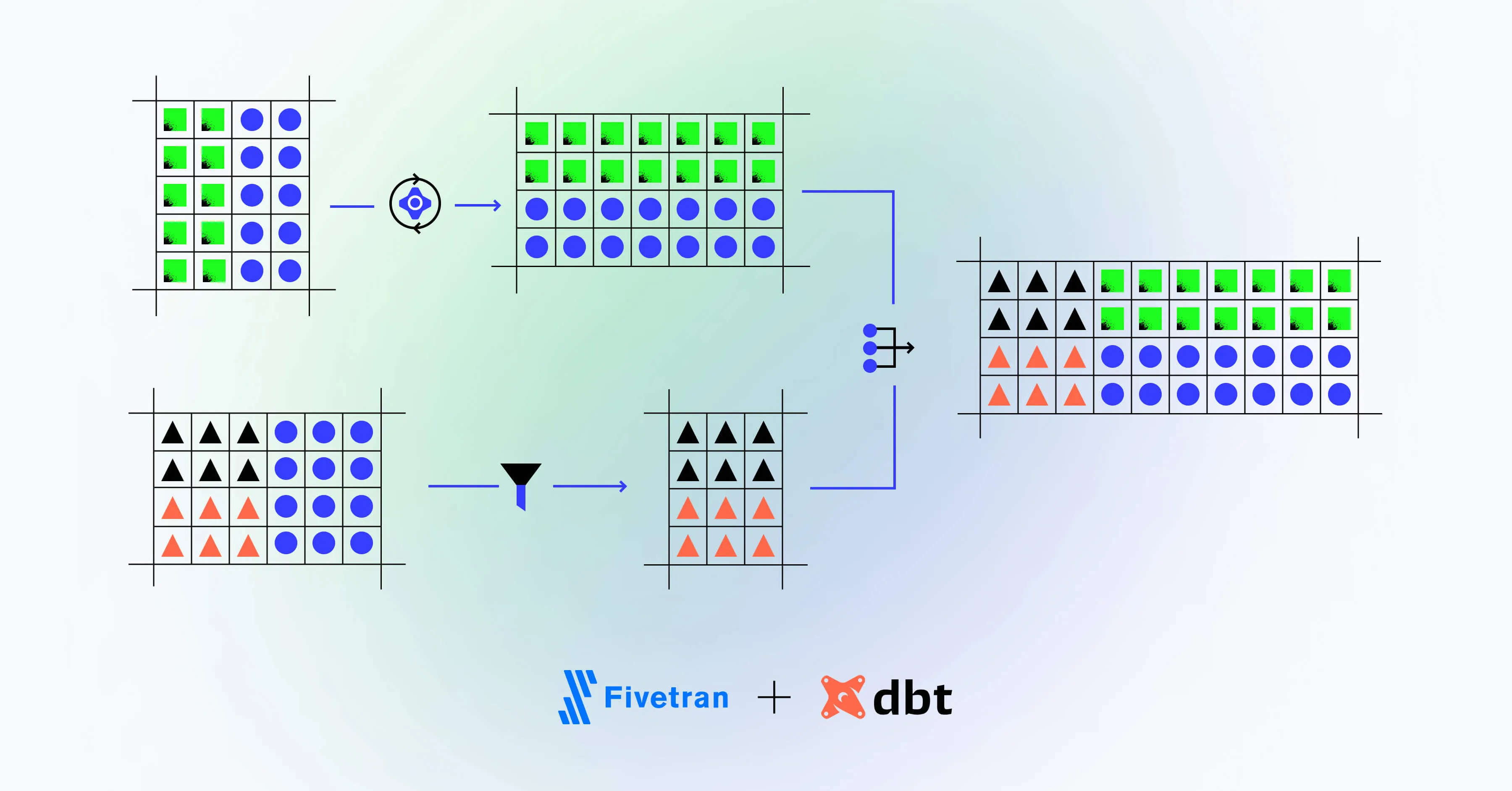
Put simply, the term “data pipeline” refers to the process of writing raw data to a centralized storage location. This is a high-level description that’s deceptively simple. In reality, pipelines are usually complex with many steps along the way.
For example, a pipeline could include transformations, or combine different data sources. It can lead to one central storage system, like a relational database or a data warehouse, or it could pipe the data towards business analysis and machine learning tools.
The central idea behind a data pipeline is that instead of simply collecting data, you get it to do something for you. For instance, your data can generate insights into sales patterns, or help identify your ideal customer. It’s important to design your pipeline in a way that makes sense for your business.
What Can a Data Pipeline Do for You?
A data pipeline consists of a number of steps to ensure that your data fits predefined schemas. It can transform the data in various ways, such as by applying methods to obfuscate sensitive customer or enterprise data. Data pipelines ensure that your company adheres to a level of security and standardization when it comes to data.
Once set up, the pipeline serves to prepare your data for processes that you want to perform regularly. For instance, you might want to use a Business Analytics tool like Tableau or Looker to create reports on a regular basis, complete with diagrams. That will allow anyone at your company to learn how things are evolving, simply by looking at a dashboard. This is known as “data democratization,” a scenario where all members within an organization have equal access to data, regardless of their technical proficiency.
Analytics reports are instrumental to data-informed business decisions. Specifically, they alert your team to trends and potential problems, which it can then react to much faster than before.
Finally, data can be used not only to chart the past and present, but also to predict future behavior. That’s the task of a data scientist. To do their magic, data scientists require a special data pipeline setup. We’ll go into that shortly, but first let’s take a look at the fuel that powers our pipelines: the data.
What Kind of Data Flows through a Pipeline?
The raw data entering your pipeline may come in a variety of formats. We often distinguish between structured and unstructured data.
A typical form of structured data is a record from a relational database. It follows a predictable format that can be easily processed. Unstructured data, on the other hand, comes in files and doesn’t follow a predefined schema. Examples include video files and text documents.
There’s also semi-structured data, which comes in internally structured file formats like CSV, JSON, or XML, and which nonetheless requires some processing to fit a relational-database format. Depending on your pipeline design, you might transform the incoming data to fit predefined schemas.
Three Reasons to Transform Your Data
There are three main purposes to data transformation. The first one is uniformity: you might want to transform your data to fit the schemas in your database or model. It could mean converting a timestamp to a date, or extracting certain keywords from a document.
Data standardization typically involves rules for dealing with faulty and missing values as well as duplicates, like deleting or replacing them. This is known as data cleansing.
Second, transformation serves to increase the data’s information value by combining different data points, either from the same source or from different ones. For example, your pipeline could receive data from a weather API and combine it with user event data, letting you understand whether certain meteorological phenomena lead to increased user activity. You could also use a library like geopandas to map a pair of GPS coordinates to the closest settlement and gain insights on user clusters.
And last, some data contains sensitive information such as users’ personal information or their IP addresses. You’ll want to mask that data to protect your customers and comply with privacy laws such as General Data Protection Regulation (GDPR) of the European Union. Masking can mean replacing or encrypting a value, or getting rid of it altogether.
Pipeline Designs
Let’s look at a typical evolution of data pipeline design at a tech startup. Many companies start out with a few team members as founders. In its early stages, a company is usually focused on developing its core product. It collects data to cater to that goal, and stores that data in one or more databases. But as the company continues to grow, its data becomes a valuable untapped resource. After some time, the company might employ a data analyst to generate reports, to be presented to investors.
But these are not the only people interested in the reports. Suddenly everyone—from HR to the frontend team—wants to have shiny graphs that chart the impact of their work. The company must now think about how to organize its data storage and ingestion process in a manner that serves analytical purposes in addition to its core product.
Data Warehouses and ETL
To achieve greater control over the data, a data engineer might set up a data warehouse: a central storage solution that serves as the company’s primary data resource. Data travels into the warehouse by way of an ETL pipeline. ETL stands for “Extract, Transform, Load” and refers to the automated process of extracting data from various sources, transforming it into predefined schemas, and loading it into the database. Data warehouses may be optionally partitioned into data marts, which cater to a specific use case or team.
The high level of engineering involved in an ETL workflow means that such a pipeline is rigidly tuned to a specific purpose. What if your purpose changes and you, as a consequence, want to adapt your pipeline? You’d have to re-engineer the entire ETL process to adhere to the new schema—a complex process that can consume a lot of time and money.
Data Lakes and ELT
These days, organizations can store their data cost-efficiently on servers provided by large companies like Amazon and Google. This is often called saving data “in the cloud.” Because cloud-based storage space is cheap, the decision about which data to keep is no longer a priority—companies can keep everything and make sense of it later.
This development coincides with a more recent data storage paradigm: the data lake. It accepts raw data of all kinds. Database records, API events, audio recordings: these all have a place in a data lake! But this changes the pipeline process. Rather than ETL, we’re now looking at an ELT process (Extract, Load, Transform). An ELT pipeline sends data from its source directly into the data lake and transforms it only when needed.
Because ELT doesn’t preprocess the data, it can load data much faster than an ETL pipeline. Additionally, the fact that all data gets stored makes data lakes a real treasure chest for data scientists. A data scientist takes the raw data and “mines” it to identify new features for predictive modeling.
Whether to settle on a data warehouse or lake comes down to your business requirements and applications. Data warehouses are better suited for reporting and analysis purposes, while data lakes can store a lot of raw data cost-effectively, making it great for machine learning. In practice, companies often use both—structured data from a data lake can be loaded into a data warehouse.
Start Building Your Own Data Pipelines
Data pipelines help streamline your internal processes and make the job of managing your data faster and easier for everyone involved.
Regardless of your company’s size or stage, Mighty Digital’s data storage solution experts are here to help at each step of your data pipeline implementation.