Building Data Pipelines with Fivetran


Share

Fivetran is a managed Extract-Load-Transform (ELT) service that allows cloud-based companies to efficiently get the most out of their data. With more data being generated and stored in the cloud, managed solutions like Fivetran emerge as an attractive and cost-efficient solution compared to hosting data pipelines in-house.
In this article, we cover the basics of Fivetran, show it in action, and explain the service’s pricing model in detail. Is Fivetran right for your organization? Keep reading to find out.
Data Pipelines: A Refresher
The term “data pipeline” refers to the process of writing data from a source (e.g. a production database) to a centralized storage location, usually a data warehouse. Steps in the pipeline include extracting the data from a source, loading it to a destination, and transforming it into its final shape.
Through the centralized data store, analysts can explore the data and get valuable business insights. Data engineering teams are usually responsible for maintaining data pipelines, and they normally run data pipelines anywhere from multiple times per week to multiple times per hour to make sure the destination data warehouse has the up-to-date information.
What Is Fivetran?
Fivetran is a managed platform for Extract-Load-Transform (ELT)-style data pipelines. It is hosted inside Amazon Web Services (AWS), Google Cloud, and Microsoft Azure public cloud environments.
The Fivetran platform takes care of executing the Extract, Load, and Transform operations on data. Companies frequently turn to Fivetran mainly if they don’t want to manage their own data pipeline infrastructure. While there are open-source tools like dbt that simplify the process of building an ELT pipeline, it might be time-consuming and expensive to maintain, manage, and debug.
Fivetran takes a Extract-Load-Transform (ELT) approach to data pipelines, as opposed to the Extract-Transform-Load, or ETL model. The company opts for ELT in their product mainly because it’s a better fit for modern cloud environments—where compute power and storage are abundant but engineering time is very limited. By shifting the Transform step to the end of a data pipeline, the ELT approach makes it easier to recover from data transformation errors, which in a traditional ETL pipeline can grind pipeline execution to a halt and cause data loss.
Fivetran is a paid service with a pay-per-use pricing model. We will cover Fivetran’s pricing in the following sections.
How Does Fivetran Work?
Let’s look at an example Fivetran data pipeline. For this demonstration, we set up a Google Sheet with musical instrument reviews from the UCSD Amazon Review Dataset. We will create a Fivetran pipeline that will extract the data from the Google Sheet and load it into Google BigQuery, a cloud data warehouse.
We start by setting up a Google Sheets connection in Fivetran. We supply the sheet’s URL, define a named range within the sheet, and share the sheet with a Fivetran service account. With the details configured, we test the connection to make sure Fivetran can access the data correctly.
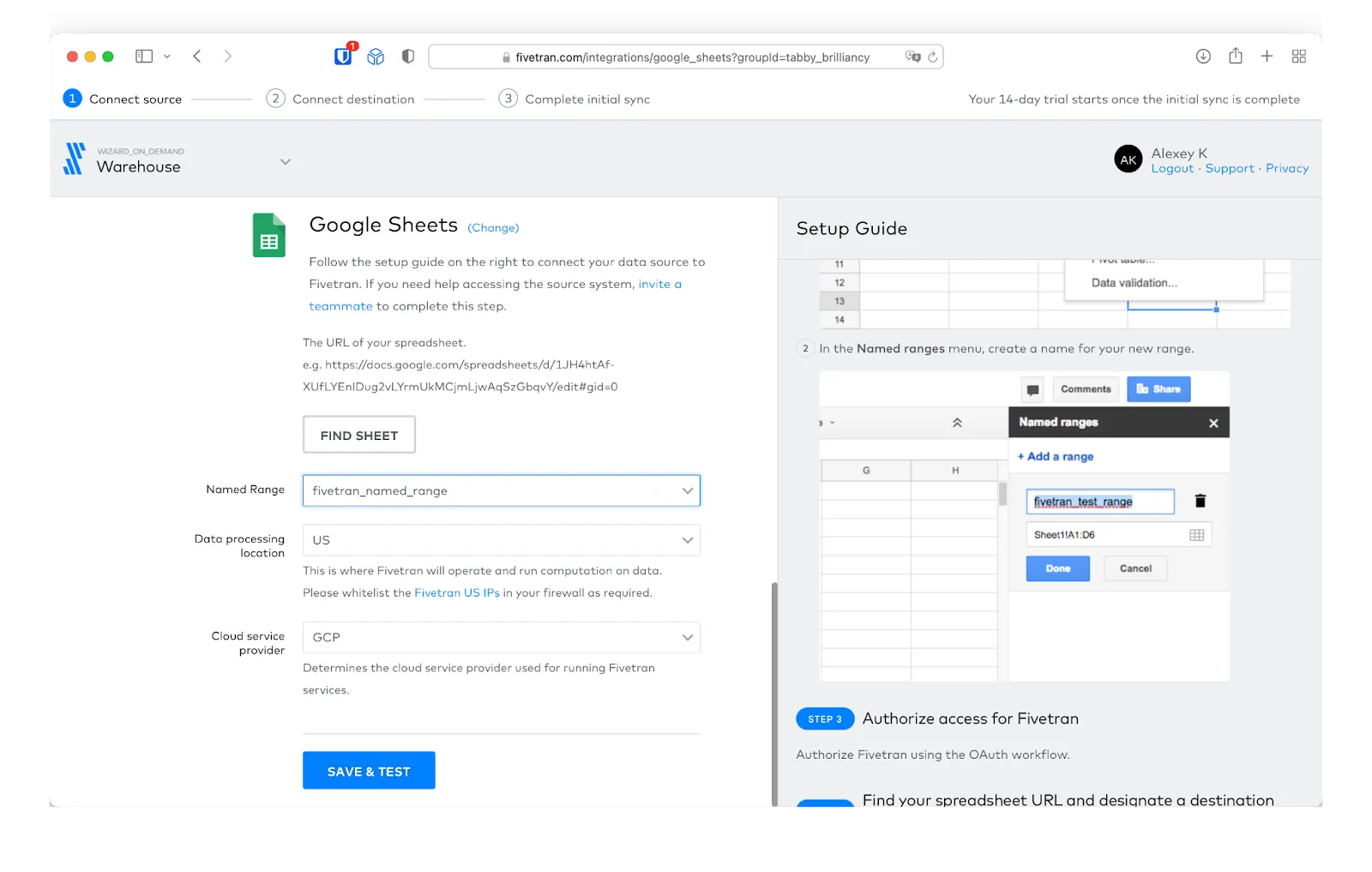
We can then save and test the connection.
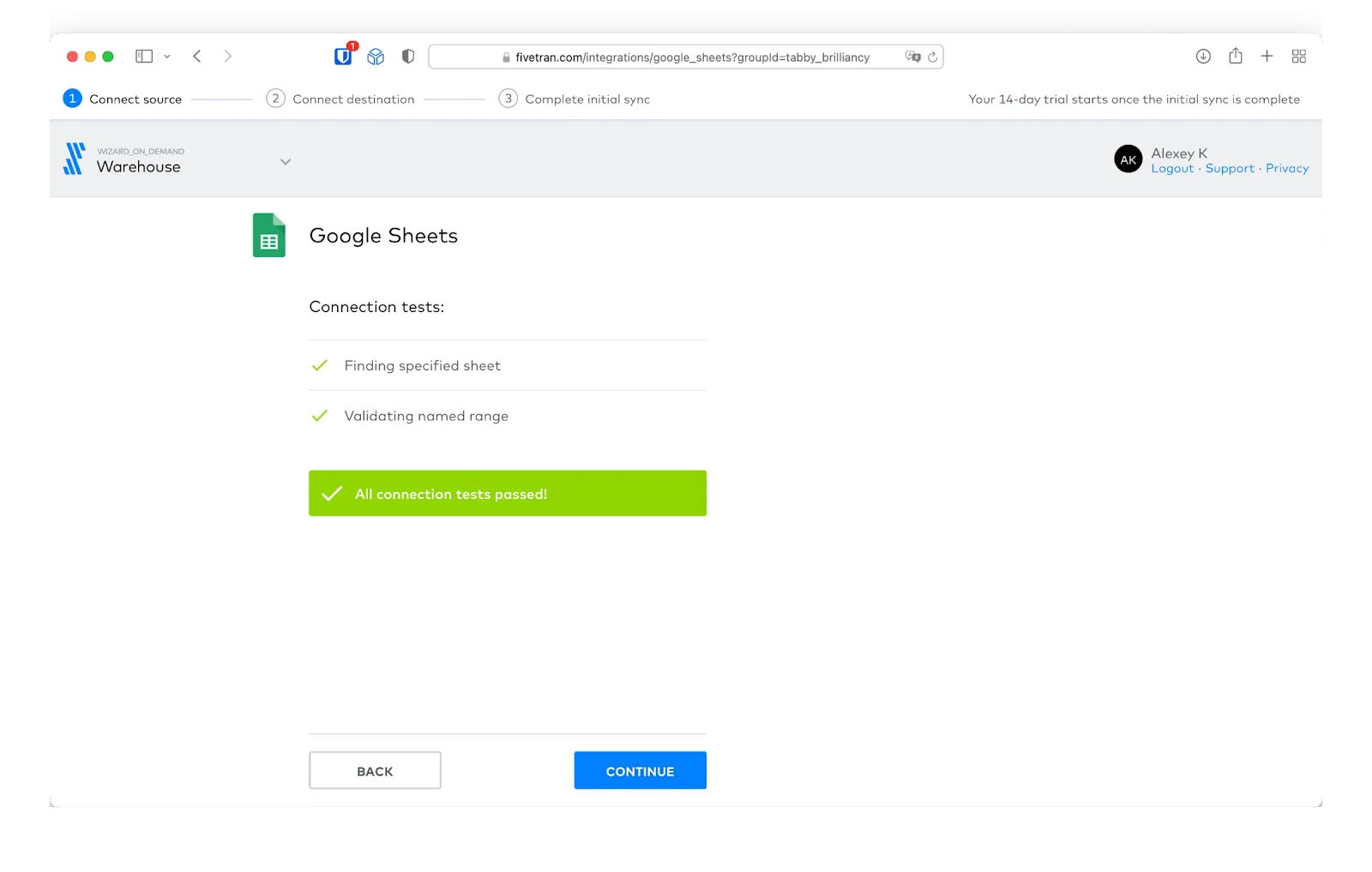
Great! We configured the connection correctly.
The next step is to connect the other side of our data pipeline—the BigQuery account—to Fivetran. To do so, we will need to assign the required BigQuery User permissions to the Fivetran service account.
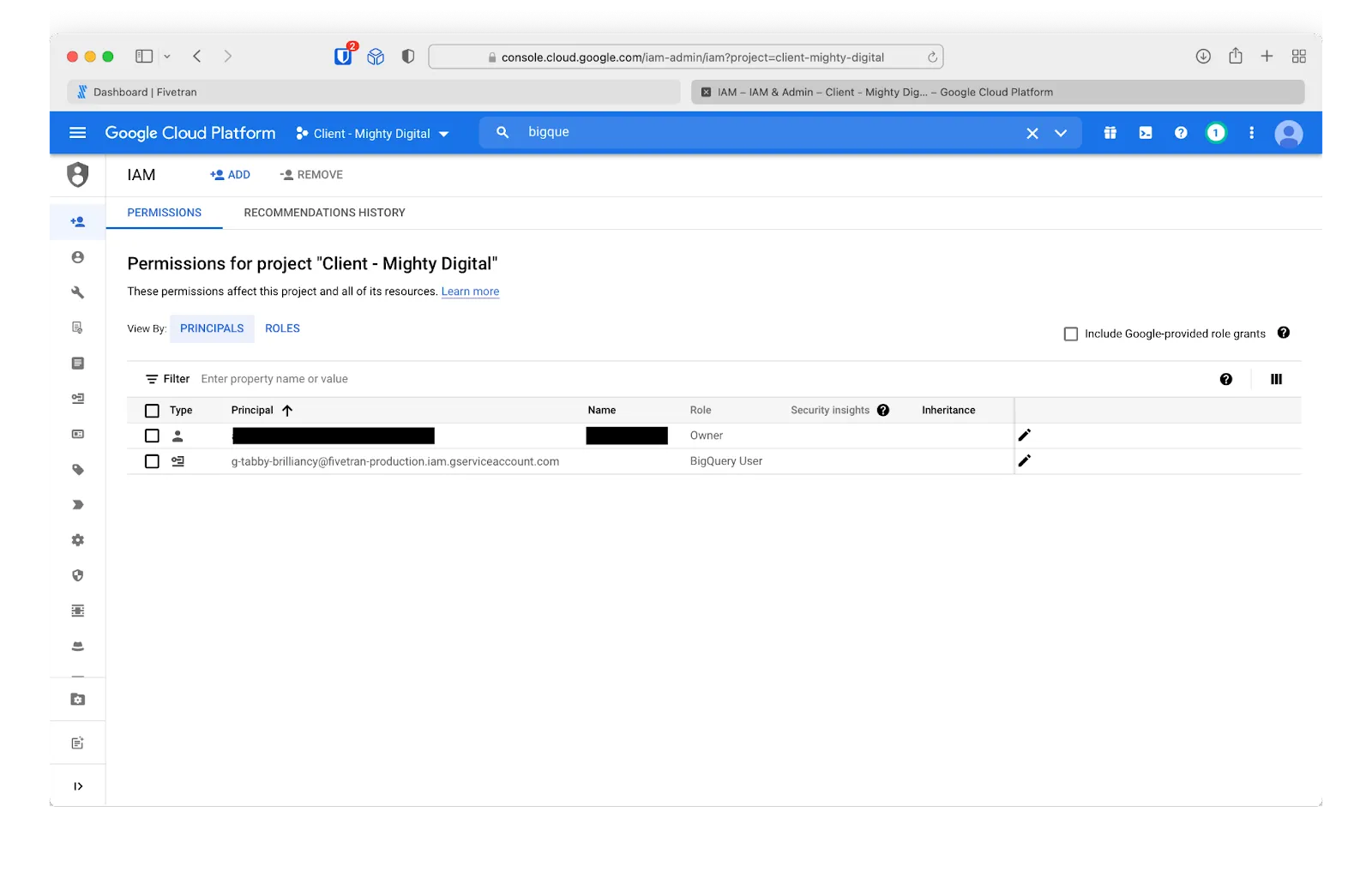
After we’ve granted the necessary permissions, we can test the connection to BigQuery.
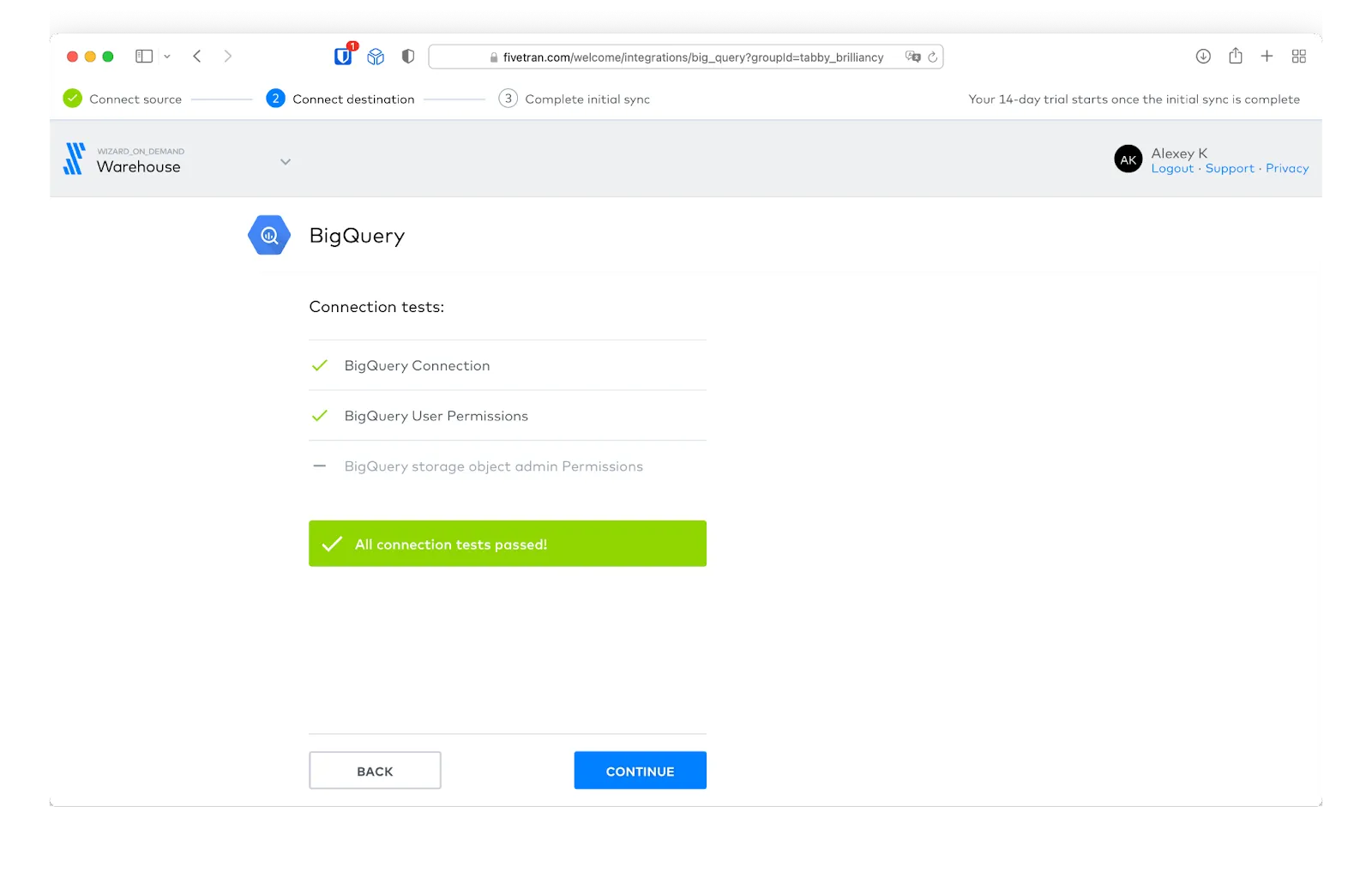
With the connection configured, we can now start our initial syncing of data from our Google Sheet to BigQuery by clicking the “Start Initial Sync” button.
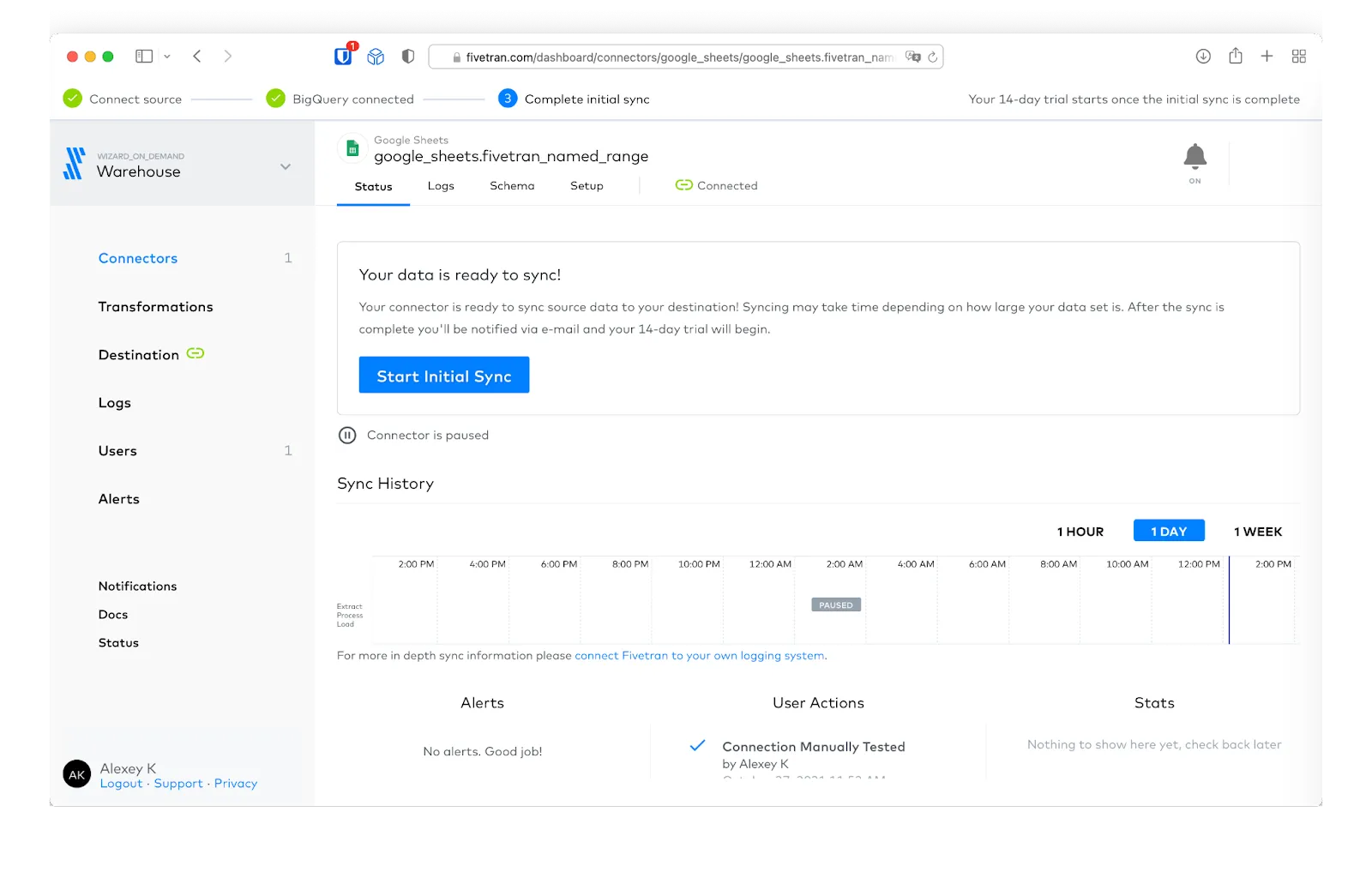
Following completion of the initial sync, we can see the pipeline statistics in the Fivetran user interface. Fivetran will show the list of most recent user actions in the pipeline and the time intervals at which the pipeline ran.
The data from the Google Sheet is now available in BigQuery. Let’s explore the data a little. For example, let’s find out how many distinct products we have reviews for. In the BigQuery console, we will write an SQL query that references the table Fivetran created for us in BigQuery.
One of the fields in our BigQuery table that can help us is asin, which refers to a product’s identification number within Amazon. If we count the number of distinct asin numbers in our dataset, we’ll have the number of products. Let’s write an SQL query for this and click “Run” in the BigQuery interface.
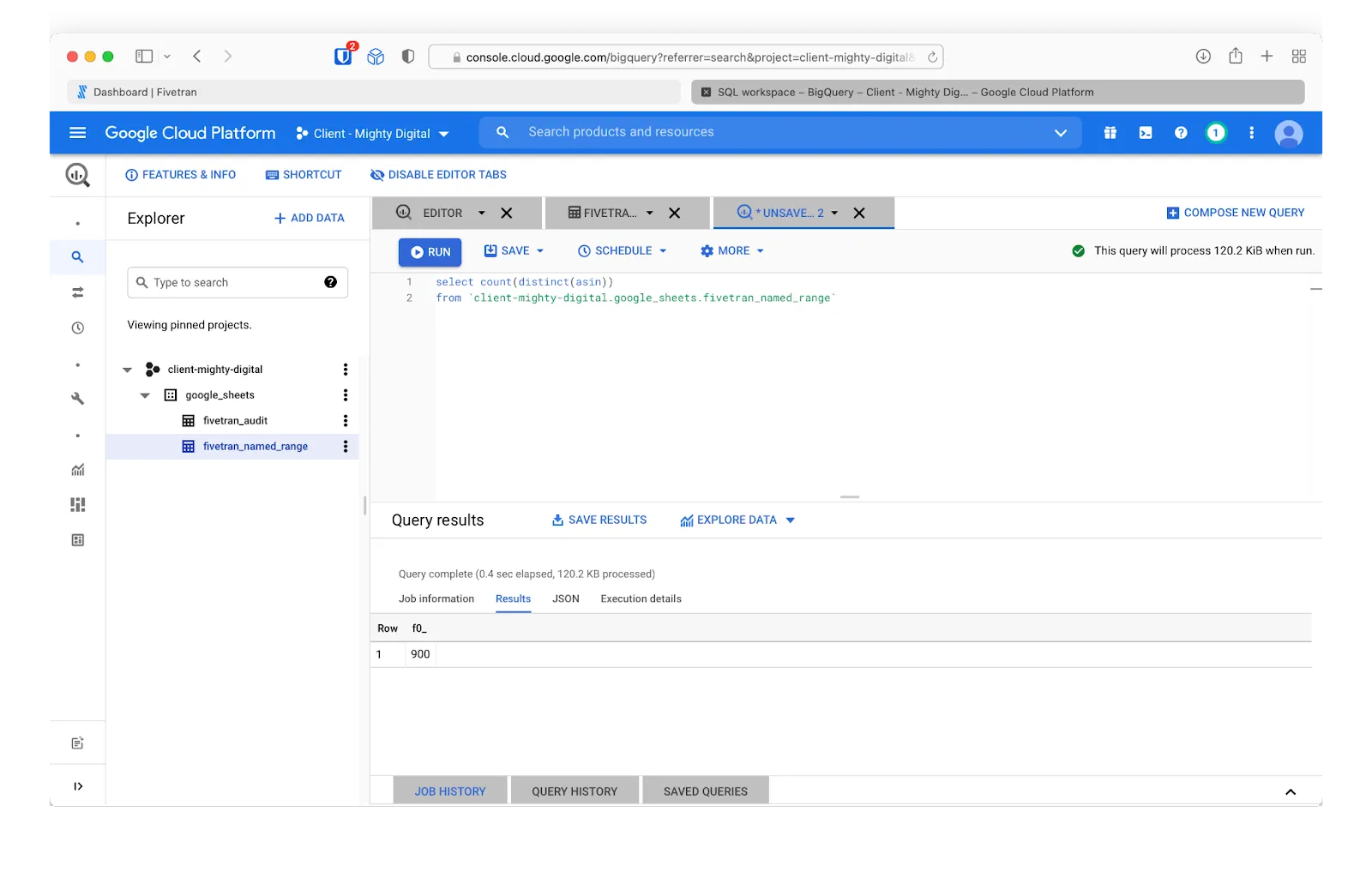
The answer from our query comes back at 900 unique products.
And now let’s try something more elaborate. Let’s figure out which products in the dataset have the most mentions of the word “perfect” in their reviews. To achieve this, we’ll write an SQL query in BigQuery that counts records that include the word “perfect,” and then sorts those records in descending order.
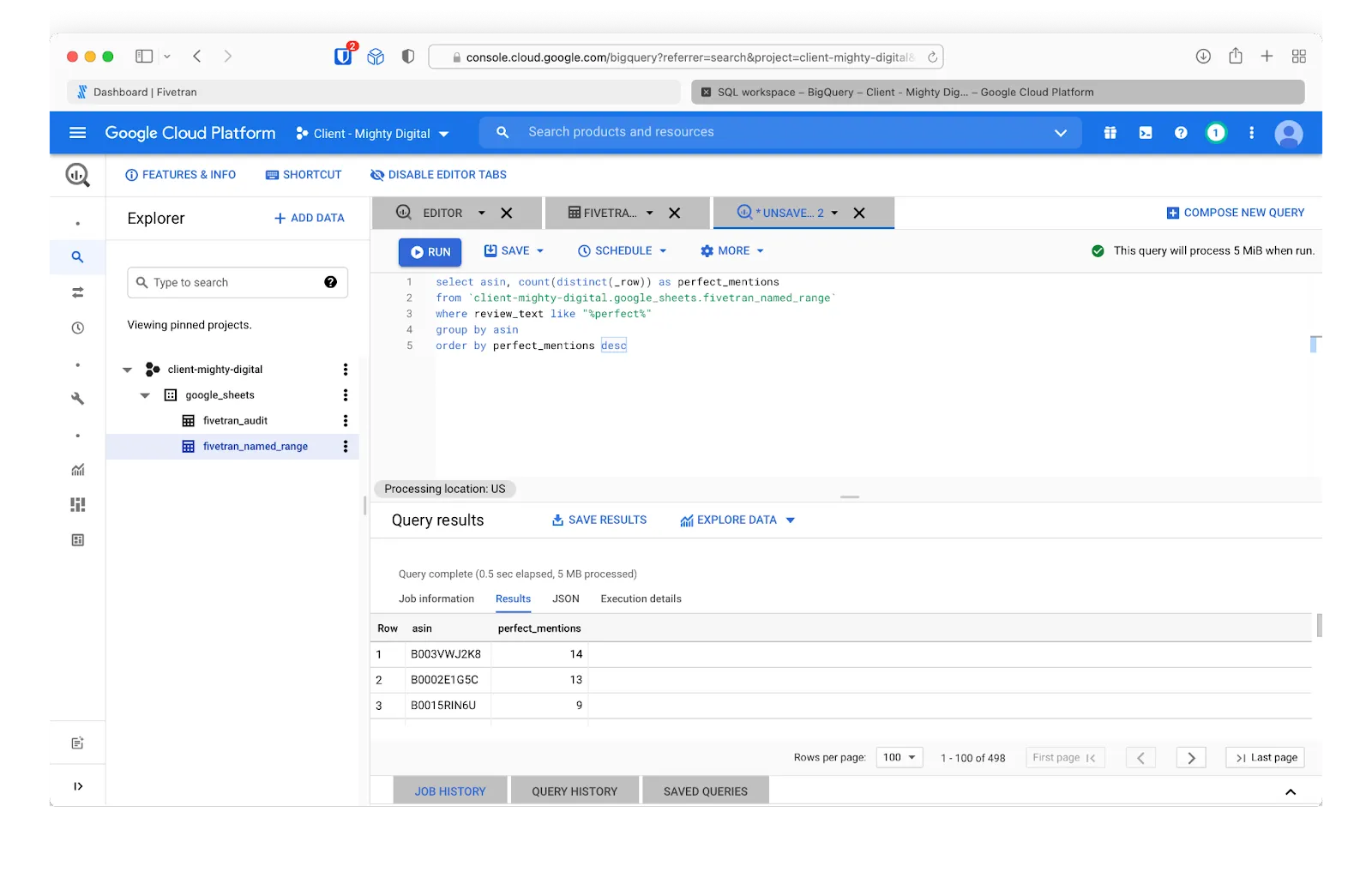
Sounds like the Snark guitar tuner could be a solid purchase! (That wasn’t an affiliate link, in case you were wondering.)
The Value of Data Pipeline Automation with Fivetran
After the initial sync, Fivetran will check our Google Sheet for changes every 6 hours, loading the updated rows into BigQuery. You can sync changes with greater or lesser frequency as needed.
It took us less than 15 minutes to set up a simple demonstration pipeline—a lot of time saved compared to building our own data pipeline infrastructure. Fivetran provides a user-friendly interface, takes care of data parsing, maintains connections, and runs the necessary data transformations. Crucially, the platform does not require you to manage any infrastructure.
Fivetran works as well with complex pipelines. The platform is built to scale to thousands of data sources and can run thousands of pipelines in parallel.
If you run a high number of pipelines, you will likely need to keep track of all changes made to each pipeline and restrict unauthorized users from changing pipeline settings. Fortunately, Fivetran implements the reporting and access controls that larger enterprises require.
Fivetran supports multiple destinations in addition to BigQuery. For input, Fivetran supports applications, various databases, files, events, and cloud functions.
Sounds valuable, doesn’t it? Fivetran is in fact a paid service, so let’s look into its pricing.
Fivetran Costs and Business Model
With a managed solution like Fivetran, you don’t have to pay for your own data infrastructure. Instead, you pay only for the resources you use through a credit-based system.
One Fivetran credit, which currently costs between $1 and $2 depending on your plan, is equivalent to a certain number of unique database rows that get processed by a Fivetran pipeline. When Fivetran processes only a few rows for you, you pay less, and when it processes more data, you pay incrementally larger amounts.
Fivetran only charges credits for active rows, that is, rows that change and need to be updated—rather than all rows in a data source. For example, if our Google Sheet has 10,000 rows and only 1,000 rows change in the month of January, we would only be billed for the 1,000 rows that changed in January, and not for the other 9,000 rows. Fivetran explains its pricing model, including edge cases, in their pricing documentation.
Let’s walk through a pricing example to give you an idea of total cost.
Example Fivetran billing structure with Google Sheets
The Google Sheet from our demonstration above contains 10,262 rows from the Amazon Reviews dataset. We were charged zero credits for the initial sync, since Fivetran charges only for active rows.
Let’s assume that 1,000 rows change per month and therefore need to be updated in BigQuery through Fivetran. This load would generate the usage of 1,000 Monthly Active Rows, or MARs. Assuming that we chose Fivetran’s Standard plan, we’ll pay about $1.50/month for our Google Sheets-to-BigQuery pipeline.
The price won’t change if the same rows are updated ten times each within the same billing month. However, if we enable Fivetran’s History Mode, Fivetran will insert each change as a new row to our data warehouse. In that case, our usage will go up to 10,000 MARs, and we’ll pay $15/month for the pipeline.
Production Fivetran billing example
Now, let’s look at a scenario that’s closer to a production environment. We’ll consider a software-as-a-service (SaaS) company with 10,000 customers that needs to load its customer tables from PostgreSQL into BigQuery for analysis. Let’s assume that there are 10 tables that we want to extract and load. We will also assume that 30% of customer records change throughout the month, and that each record that changes does so an average of five times per month. We’ll need History Mode turned on, which will allow us to run historical analysis in our data warehouse.
Under this scenario, we would see the following usage in our Fivetran account:
Usage = 10 tables x 10,000 rows per table x 30% of rows updated x 5 updates per row = 150,000 MARs
The pricing for our usage would be as follows:
Pricing = 150,000 MARs / 1000 MARs per credit x $1.50 per credit = 150 credits x $1.50 = $225/month
Keep in mind that BigQuery usage and the network costs for data transfer into BigQuery are billed separately in our Google Cloud account.
Who should consider using Fivetran?
Fivetran is a managed platform, and as we saw above, it can be a costly one if you have a lot of data to sync.
Considering the total cost of service, Fivetran can be a great fit for companies that don’t want to manage their own data pipeline infrastructure, for example, growth-stage startups that need to focus on their product. In many cases, the Fivetran credits you would need to run complex pipelines frequently would end up being less than the costs of maintaining data pipelines on your own infrastructure, when you include compute costs and development time required.
Thanks to Fivetran’s pre-built data integrations, data engineers can save a lot of time by choosing to use Fivetran over building their own integrations for relevant data sources and destinations.
In addition, building new data pipelines with Fivetran is a user-friendly experience. A non-technical user can perform most tasks in adding a new pipeline, as we have seen in the example above. Companies that want to enable less-technical users to build data pipelines will benefit from using Fivetran for this reason over a self-managed, difficult-to-use solution.
Potential Fivetran limitations
Keep in mind that Fivetran isn’t the right choice for every organization. The platform only supports a subset of all data sources and destinations out there. If you happen to be using the data stores that Fivetran supports, great; otherwise, you’re out of luck.
In addition, you can’t use the Fivetran dbt packages unless you’re using one of the supported outputs (BigQuery, Databricks, PostgreSQL, Redshift, Snowflake). If you’re not using one of these sources, you’ll be limited to Fivetran’s built-in, less flexible data transformation options for your pipelines.
Fivetran’s architecture follows best practices, and that means that you could not adapt it to your needs if you needed special functionality in your data pipelines.
Another limitation to keep in mind is related to debugging. Fivetran is a managed platform, and while you can instrument logging with Fivetran’s logging connector that writes all logs to BigQuery, debugging pipelines might still be a challenge. If something with your Fivetran pipeline goes wrong, you’ll need to rely on information in the Fivetran error messages or work with the Fivetran support team to figure out the issue.
Is Fivetran for you?
So, is Fivetran the right solution for you?
It depends! Mighty Digital is a Fivetran certified partner, and we can provide an expert opinion that takes your organization’s needs into account.
If your organization is considering Fivetran, we offer the following services:
- Estimate the future cost of your Fivetran subscription.
- Design pipeline architecture to minimize cost and maximize performance.
- Implement pipelines in Fivetran following best practices.