How dbt Helped Us Significantly Reduce Our ETL Costs

Share

Building data pipelines is not a simple task. Moving data from one point to another reliably and quickly is vital, and must be the focus of any pipeline in order for it to supply actionable data when it is needed.
This article will outline how Mighty Digital is using the dbt software package to simplify our ETL toolchains, reduce costs, and improve data handling for both ourselves and our clients.
Introduction
Over the past decade, Mighty Digital has built a myriad of different types of ETL pipelines for a multitude of different environments. We built these pipelines using various technologies, software stacks, and methodologies. These differences accounted for the data being collected, the transformations required, and the best tools available at the time of implementation.
One of the features common to all of the products we have used in our pipelines is the use of SQL (Structured Query Language). SQL transcends the differences across almost all of the possible data and engineering stacks, domains, and even employee roles.
SQL is ubiquitous — and for good reason. The SQL syntax is flexible and readable, powering the queries for simple web applications and big data analysis applications alike. It was developed in the mid-1970s and is still being used and improved on, making it a reliable standard with widespread applications. Engineers, business analysts, and C-level executives can invest the time needed to become familiar with the language, knowing that the skills they develop will remain practical and applicable for future projects and roles.
Why do we build data pipelines?
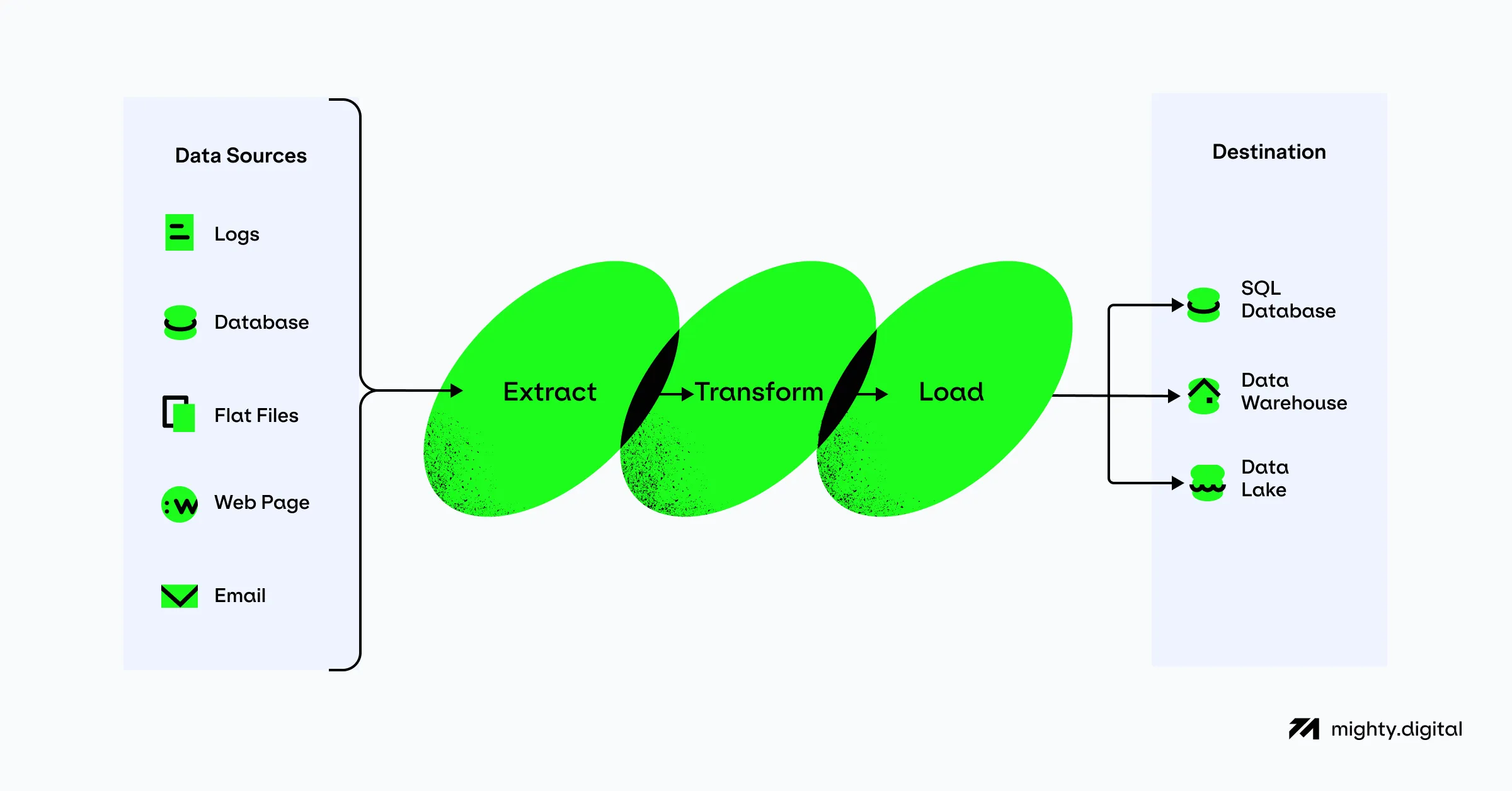
Data pipelines are built to move data from point A to point B reliably and quickly while keeping engineering and maintenance costs as low as possible. Minimizing costs is a priority, as when data volumes begin to increase, the costs of the infrastructure transporting and hosting that data will also increase. This can potentially cause a future bottleneck not in the infrastructure itself but rather in the affordability of the implemented system.
Put simply, the more valuable data you collect, the more it costs to process and store, and there is a danger of reaching a point of diminishing returns. Spending the time and investing in professional expertise to identify and properly implement even small cost optimizations in data pipelines can yield great benefits in the long term.
What is dbt?
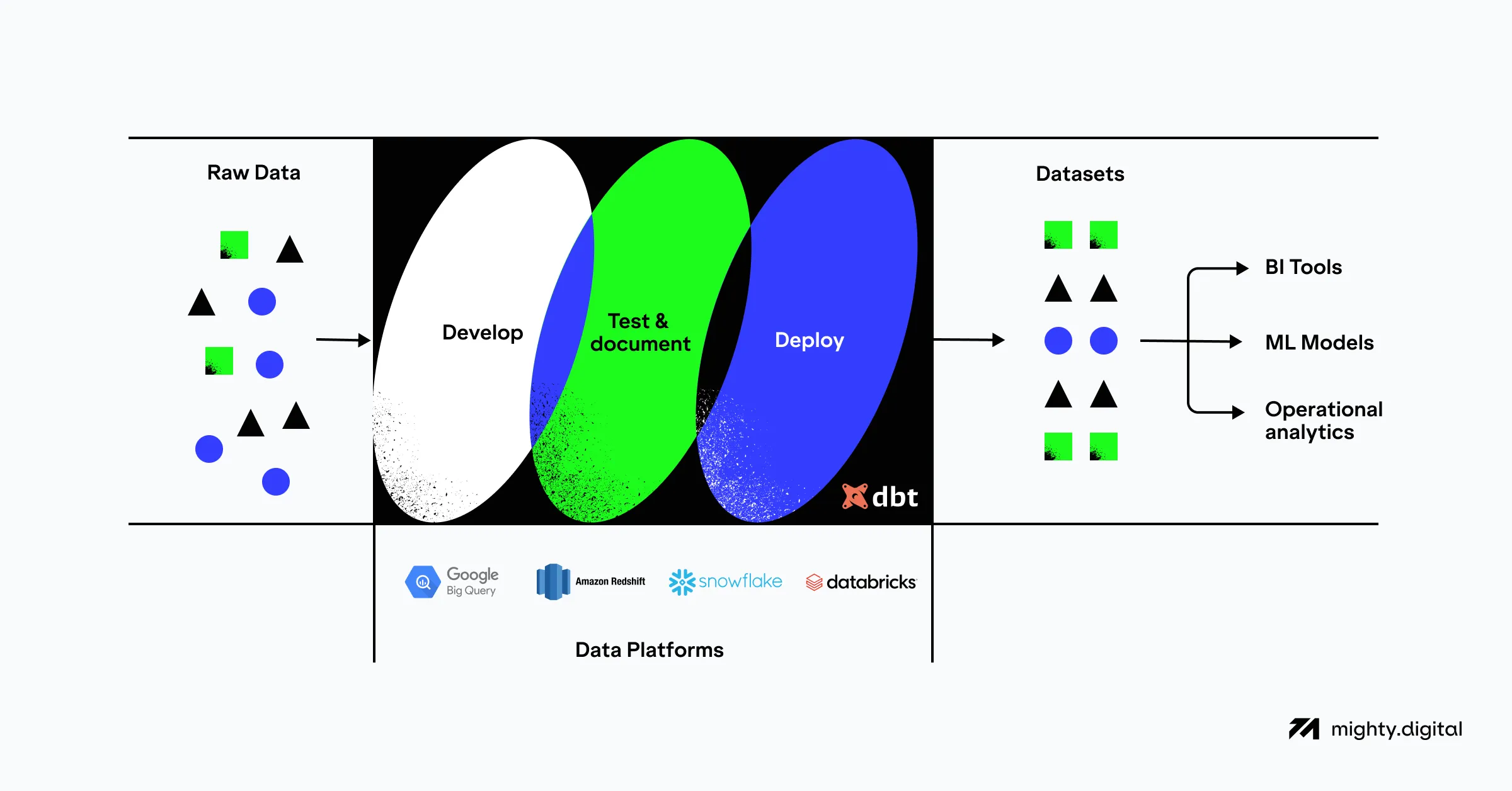
dbt (data build tool) is an elegant software tool that allows analytical engineers to transform the data in their warehouses by simply writing select statements. dbt provides the transformation of these select statements into tables and views.
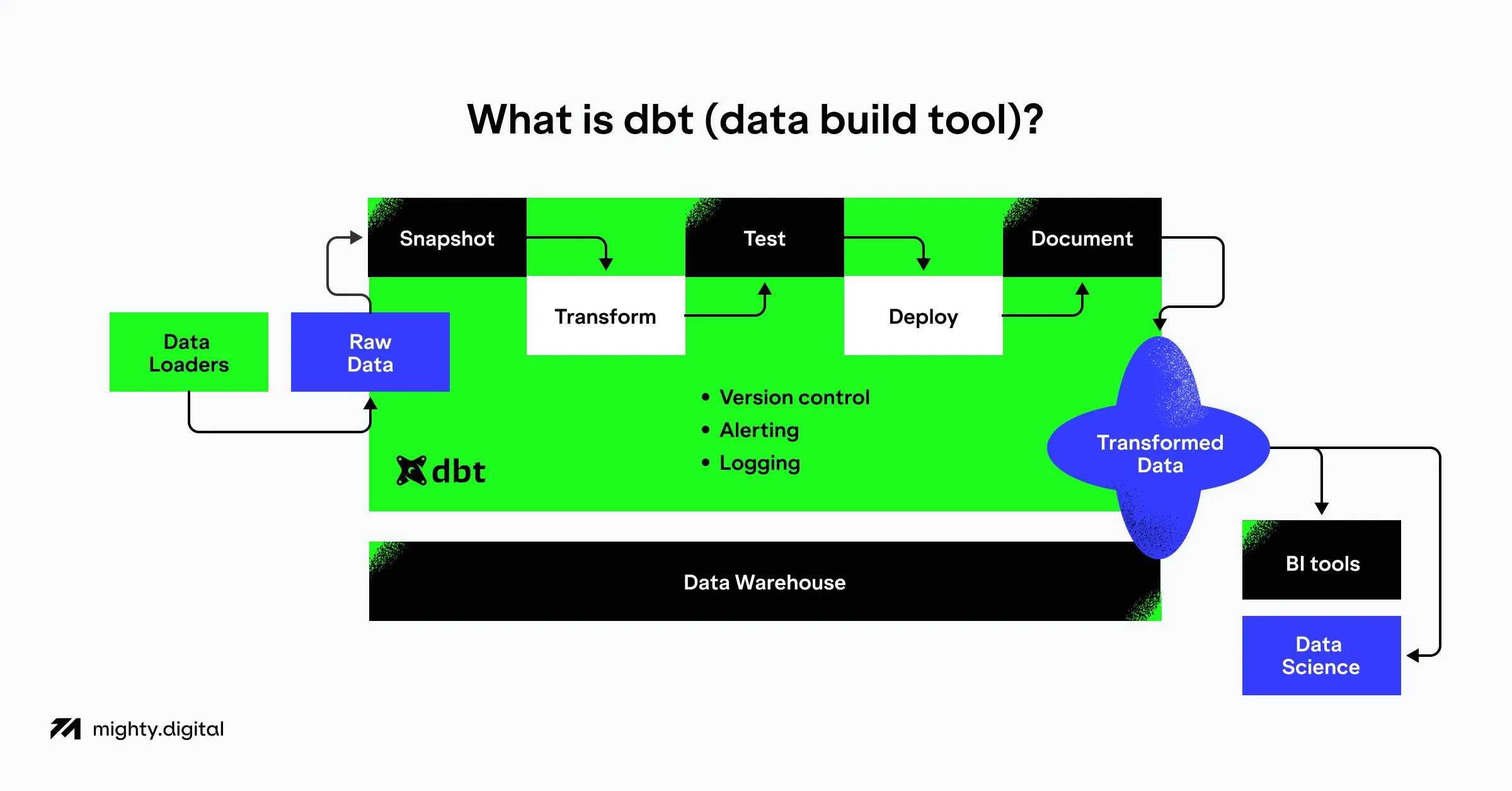
dbt performs a T function in ELT (Extract, Load, Transform) processes
- it does not extract or load data. Still, it is extremely good at transforming data already loaded into your warehouse.
dbt simplifies your ETL toolchain
Compared with competing solutions, ETL stacks built with dbt require fewer technologies to achieve the same — and often improved — outcomes.
Throwing more tools at a problem may achieve short-term results. However, the more infrastructure there is, the more that can go wrong. dbt allows you to do more with less, lowering the cost of both building your initial ETL pipelines and maintaining and updating them in the future.
By using a simpler toolchain, you can reduce technical debt – the future cost of fixing mistakes made in the present. Technical debt can result from poorly informed decisions when choosing the tools that power your business, or from rushed implementation that leads to shortcuts or simple mistakes during the development of solutions.
dbt streamlines your ETL operations
In addition to simplifying the ETL pipeline infrastructure, dbt also helps to streamline the day-to-day operations required when interacting with the data from these pipelines.
Data mesh is a modern approach to data handling that focuses on the pieces of data that make up the whole rather than approaching the data as a monolithic entity. Easily implemented ETL pipelines make it simple to set up multiple pipelines for various data sources, each tuned to get the desired outcomes.
Implementing dbt with SQL databases combines powerful ETL tools with standard, widely understood syntax for a robust, accessible data toolchain.
How we used it
At the outset of our most recent project we found that we were spending too much time configuring and orchestrating the various products that were being used to build the required data pipelines. We also raised concerns with our client that this system could become prohibitively expensive to run in the long term, as the amount of data being collected was expected to increase dramatically.
Our initial stack was built on AWS, relying on Kinesis streams for piping data and AWS Glue for the heavy transform workloads. Lambda functions were also included to fill in some gaps before the data was warehoused in Redshift.
We decided that, alongside the development outlined above, we would try something different — implementing dbt to see if the same results could be achieved with a smaller, easier-to-manage set of tools that would cost less to maintain in the long term.
Starting small
To ensure that dbt was able to do what we needed and that our time was not wasted, we started small. dbt was used to create top-level representations/models from a limited selection of the data for our data analytics and business teams. We used the resulting pipelines to build a set of new domain-specific dashboards within our reporting layer.
Not only did we confirm that dbt was able to do what we needed it to for our specific use case, but we also found that it was capable of more than we had initially intended. In addition to creating the top-level representations and models of the data, we started adding tests to validate that the information being represented remained intact and conformed to a specific set of rules.
This approach resulted in immediate benefits — we were alerted about malformed data before it even made it to the dashboard’s users, saving us a significant amount of engineering time and maintaining our data team’s reputation for perfection.
Data migration
Ever since we realized the benefits of this approach, we have been slowly but surely migrating our other incoming data pipelines to dbt-based solutions as well.
Instead of dumping raw data into S3 and hoping Glue will take care of everything for us, we now look at incoming data more carefully, storing it in a more structured and organized way. Data can be processed and sent directly to Redshift tables, while irregular or raw data is stored on S3 file-based storage and loaded as an external table using Redshift Spectrum. This allows us to keep both structured and unstructured data in its initial form while also making it queryable and accessible within Redshift.
One of dbt’s best features is its amazing declarative way of creating data models, which are deployed to the warehouse as views. Rather than just giving us a snapshot of the data at a given time, it provides us with a window to the actual current data. This is a powerful tool for our analysts, who can now work with live data as it is collected.
Real-world results
The data validation and schema conformity checks provided by dbt were a monumental improvement over our previous ETL pipeline, which required significant time and effort to implement a comparable monitoring solution. The toolchain is now simpler, and the costs of maintaining and operating the system are expected to be much lower in comparison.
The ability to interact with instantly accessible, live data — something we had not been able to achieve with our existing ETL tools — gave us a big confidence boost to continue expanding and improving in this area. We are continuing to implement dbt into our own pipelines to ensure they remain flexible and affordable and that they are able to assist us in producing the data results our clients expect.
Conclusions
Fully leveraging flexible, robust tools to build minimalist software stacks allows technical teams to focus on better tailoring their pipelines to their data, providing analysts with better information from which to make decisions.
Reducing infrastructure requirements prevents prohibitive operating costs from becoming a future bottleneck as the amount of data being collected, processed, stored, and queried increases.
dbt allows for simpler toolchains with less infrastructure. It also enables fast adoption by providing a familiar interface using industry-standard and widely adopted technologies like SQL.
Mighty Digital is an industry leader in data-informed growth for digital brands. We are constantly testing new methods and technologies to ensure we get the most out of every bit of data collected so that our clients can realize the full potential of their market.
Get in touch with us today if you have any questions about how we can help your business grow with our innovative, industry-leading data practices.