Meltano: the framework for next-generation data pipelines

Share

Meltano is an open-source, full-stack data integration platform that is challenging established commercial products in the data processing space. Meltano is built on top of industry-standard and open components and encourages DataOps best practices, making it a powerful platform for building ELT pipelines.
This article will explore how Meltano can be leveraged to build next-generation data pipelines. It also includes working code examples that demonstrate how to build a data integration pipeline using Meltano in just a few steps.

What is an ELT pipeline?
An ELT pipeline refers to a set of processes for converting messy and non-actionable data into a format that analysts, data scientists, salespeople, and other end users can access and draw insights from. The acronym “ELT” refers to the three steps taken in this type of data pipeline:
- extracting raw data from a source
- loading it into a centralized database
- standardizing it through various transformations.
The finer details of each step will vary depending on the data you are collecting and the results you want to achieve with your ELT pipeline.
For example, if data is being collected from multiple data sources in different formats, each data feed will require a custom script for scheduling downloads, a custom data loader that massages the extracted data into your database’s schema, and a specialized script for transformation.
While it’s crucial for data-oriented organizations to have reliable data ingestion tools in place, getting pipelines to run smoothly under such scenarios requires considerable effort. Carefully chosen and properly implemented tools are required to ensure that data is properly collected, processed, and stored.
Meltano is one such tool, thanks to its DataOps-friendly approach to building data pipelines and has a lively online community of data professionals who provide support and work on new ideas to get the most out of your data.
What is Meltano?
Meltano is a self-hosted ELT solution created by GitLab. Initially made for internal use by the GitLab data team, Meltano quickly grew into an independent entity when its team became aware that many organizations were facing the very issues that Meltano intended to solve.
Data integration tools are not a new concept, with commercial products such as Snowflake and Databricks offering hosted ELT solutions. But unlike its hosted peers, Meltano’s mission is to challenge the pay-to-play status quo and democratize data workflows by making ELT platforms open and freely accessible to everyone.
Many businesses cannot afford the fees charged by the proprietary tools that currently dominate the ELT market. As companies start ingesting more data, high maintenance costs can quickly push their financial investments into the territory of diminishing returns.
Tools like Snowflake are limited to being hosted on supported major cloud providers, which can incur additional hosting costs and significant data transfer charges, especially if you aren’t located in a region with a proximal data center. This prevents many businesses from realizing the full potential of their data.
Meltano’s answer to the above is an open-source tool that streamlines every step of the data ingestion workflow. Meltano’s open-source model means it’s free to use. Likewise, Meltano allows you to process your data locally, so you don’t need to lease services from third parties, and have your sensitive data ever leave your systems.
By using Meltano, you ensure that you stay in control of your data, including how it’s processed and—an increasingly important concern for compliance purposes—where it’s processed.
A true ELT solution
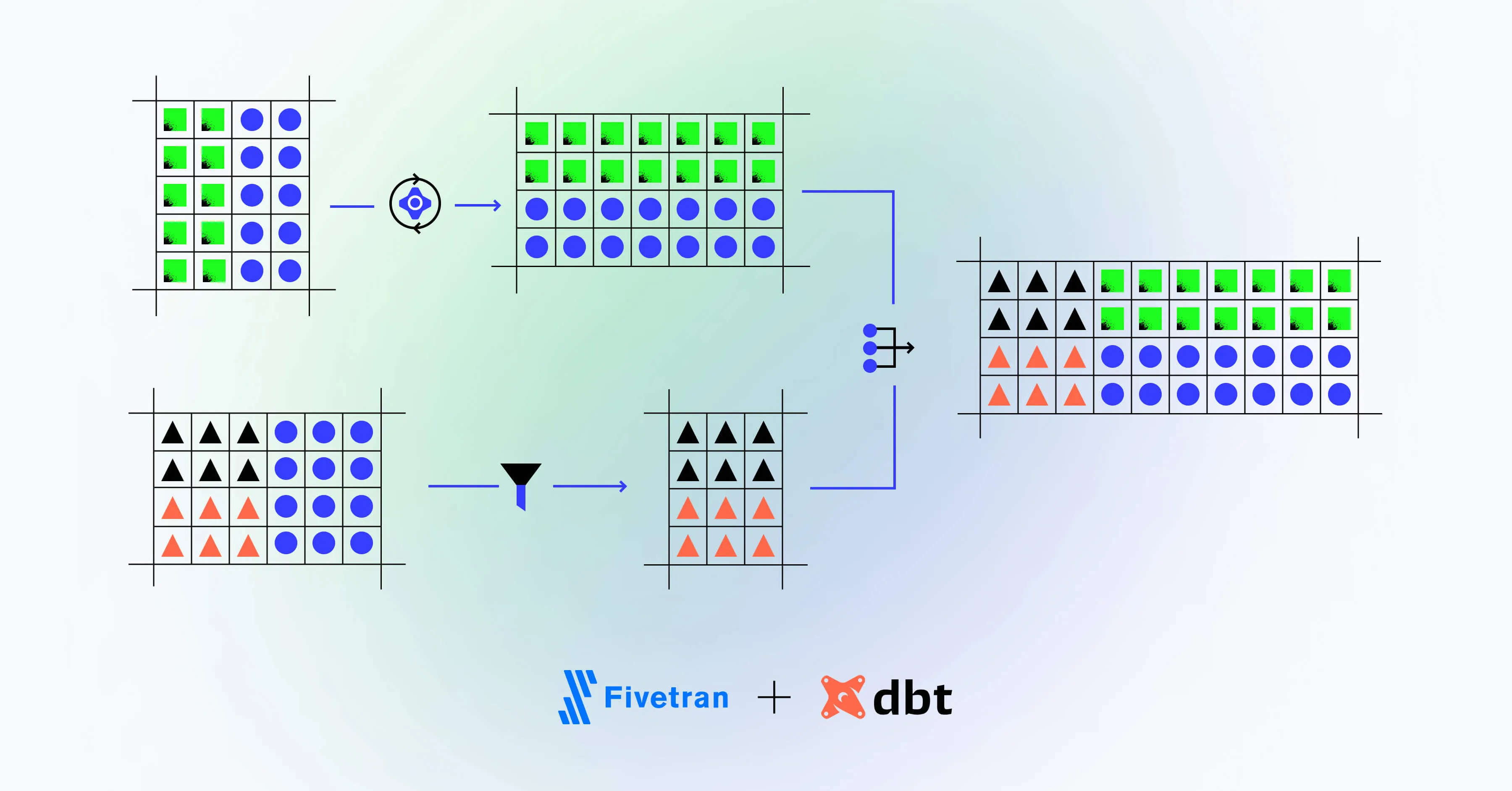
Meltano stands out for its ability to offer solutions at every step of the ELT pipeline.
Traditionally, data pipelines would struggle in terms of data accessibility. Simply getting data from one place to another would require a lot of time, which could be better spent on deriving insights. By adopting DataOps principles and a distributed data mesh approach, Meltano brings together the data industry’s best practices to overcome problems common to data systems. This results in accelerated workflows, shorter cycle times, and generally more reliable data platforms.
Meltano builds pipelines in a modular fashion, combining open-source tools like extractors from Singer’s taps, loaders from Singer’s targets, and transformers from dbt. These tools are among the best the data analysis community has to offer. For example, utilizing Singer provides an underlying extraction and loading protocol that makes data ingestion a breeze, and dbt makes transformations as simple as writing SQL queries.
Meltano projects are stored as directories on your computer or in Git repositories, with the project configurations being stored as plain text files. To make a change to any part of the pipeline, you simply adjust the corresponding configuration file. In true DevOps fashion, you can apply any modern software development principle, including version control, code reviews, and CI/CD, to your Meltano projects.
This structure means that Meltano’s pipelines are self-contained, and the history of changes is tracked from start to finish. You don’t have to hunt for external resources to implement new solutions or update a given step of the pipeline.
Meltano in action
The example below demonstrates the ease with which you can use Meltano to create a data integration pipeline. To set up Meltano locally on your computer, follow Meltano’s official installation guide.
First, we’ll run a command to initialize a Meltano project named meltano-demo and create the project’s directory:
meltano init meltano-demo
cd meltano-demoNext, initialize the pipeline’s components. First, we’ll create an extractor that pulls the data from GitLab:
meltano add extractor tap-gitlabNext, we’ll configure the extractor to pull the data from projects in meltano/meltano. Additionally, we’ll instruct the tap to only extract data starting from June 1, 2021, and only the data under the “tags” stream:
meltano config tap-gitlab set projects meltano/meltano
meltano config tap-gitlab set start_date 2021-06-01T00:00:00Z
meltano select tap-gitlab tagsWe’ve finished setting up the extractor! Now, we’ll build a loader to store the data in a JSONL file:
meltano add loader target-jsonlIt’s necessary to specify the target folder where the resulting JSONL file will be stored. We can configure this manually by opening the meltano.yml file and adding the required lines ourselves. Alternatively, we can run the following commands:
meltano config target-jsonl set destination_path my_jsonl_files
mkdir my_jsonl_filesWith the extractor and loader in place, all that’s left is to combine them into a pipeline:
meltano elt tap-gitlab target-jsonlFinally, to verify the pipeline’s successful execution, we can use the following command to output the top tag from the created file to the console:
$ head -n 1 my_jsonl_files/tags.jsonl{"name": "v1.78.0", "message": "Bump version: 1.77.0 \\u2192 1.78.0", "target": "802654553892e7bf8cc4fee78bce259a7fb741ab", "commit_id": "b45b987ed6d9c50d89da418bb916556d0efc2f10", "project_id": 7603319}Et voilà! It took us just ten commands to create a fully functional data integration pipeline using Meltano.

Meltano implementation best practices
At Mighty Digital, we have been successfully leveraging Meltano to implement robust and flexible data pipelines. We follow several practices that we think are worth adopting in your own data processing journey. The following tips will help you build your ELT pipelines and make the most of your data.
Tip 1: keep dbt transformations separate
We recommend keeping each pipeline’s source-centered and business-centered dbt transformations separate. This measure might seem unnecessary, but making a clear distinction between the contexts and pipelines pays off in the long run, as segregating transformations simplifies testing and validation.
You can validate sources separately from models in addition to conducting schema tests, referential integrity tests, or your own custom tests. This goes a long way toward building a reliable data platform that reflects the true state of your business’s data.
Tip 2: build reusable components
You will likely be working with all kinds of data stored across different databases and formats—including Excel spreadsheets, RFC 5322 files containing email data, multiple APIs, and custom data formats from third-party sources.
You will need to write custom code for extractors and loaders so that this data can be accurately processed. To minimize the effort required to maintain these components, aim to make them reusable.
Reusable data integration is the main idea behind Singer, and industry professionals like Mighty Digital often have their own existing components that can be used or adapted, which saves time and costs when establishing new pipelines.
Tip 3: don’t skimp on monitoring and logging
Don’t overlook the importance of monitoring and logging parts of your data cycle. Putting proper monitoring and logging tools in place early on will help you stay informed about your infrastructure’s processes. This will ultimately mitigate any problems that may arise later on, as your team will be able to troubleshoot them much faster.
Tip 4: establish success criteria
How do you evaluate the success of your data platform? One way is to establish success criteria by which to measure your business’s performance. Consider establishing benchmarks for cycle time, speed to market, and/or developer productivity, and optimize accordingly.
Tip 5: start small
Start with a small project or proof of concept using a subset of your data. This project is not meant to implement the entire solution, but rather to prove that its implementation is feasible in the first place. Beginning your project on a microscale lets you improve upon your idea and serve as a strategic roadmap for future development.
Start implementing Meltano for your business
There are clear advantages to using Meltano over its commercial competitors when building data platforms. Meltano is a powerful tool that is simple to maintain, and its open-source model ensures that it is both flexible and budget friendly.
The open-source nature of the software also contributes to the platform’s longevity—bugs are identified and fixed by the community, and advice is widely available. Anyone can write custom plugins for the platform to extend functionality or support additional data sources, future-proofing support for new data sources.
As demonstrated in this article, Meltano pipelines are easy to implement. However, if there are many data sources and highly complex transformations to deal with, even the simplest tools can become overwhelming for inexperienced users.
At Mighty Digital, we help organizations leverage Meltano to power their data integration pipelines. Our data infrastructure and processing experts are experienced in Meltano implementations and can implement robust, accurate pipelines of any complexity.
Get in touch with a Mighty Digital expert today to find out how we can help you make the most of your data.